背景
- 有些项目不支持相对路径加载,只能在线下载模型权重。
- 根据观察,可以将离线下载的模型,通过脚本,转成cache需要的格式。
- 根据huggingface官方说明,10MB以上文件,自动走lfs。链接
- 观察
.cache/huggingface/hub下载的cache,发现了下面的规律
models--deepdml--faster-whisper-large-v3-turbo-ct2
├── blobs
│ ├── 0351d1d6870005e865747b781b5d7c23ea0459cd
│ ├── 0adcd01e7c237205d593b707e66dd5d7bc785d2d
│ ├── 17456db595adc78a973f97d69d8cb50bc87c0b1c
│ ├── 931c77a740890c46365c7ae0c9d350ba3cca908f
│ ├── 9f33237d3eca0db41b9ac80fd60b4b843d61f923
│ └── e76620f83d5f5b69efd3d87e3dc180c1bd21df9fbebacfd4335e5e1efcc018da
├── refs
│ └── main
└── snapshots
└── 44cbbd1adefe7387c83df88963a6d9ac4c9adea5
├── config.json -> ../../blobs/0351d1d6870005e865747b781b5d7c23ea0459cd
├── model.bin -> ../../blobs/e76620f83d5f5b69efd3d87e3dc180c1bd21df9fbebacfd4335e5e1efcc018da
├── preprocessor_config.json -> ../../blobs/931c77a740890c46365c7ae0c9d350ba3cca908f
├── README.md
├── tokenizer.json -> ../../blobs/17456db595adc78a973f97d69d8cb50bc87c0b1c
└── vocabulary.json -> ../../blobs/0adcd01e7c237205d593b707e66dd5d7bc785d2d
- refs存放最新项目最新分支(一般默认是main),main文件的内容则是最新的commit_id
- snapshots存放最新commit_id文件夹,然后这个文件夹下面存放一些软链接,链接到真正的文件。
- 真正文件的文件名,是以git hash-object(非lfs文件)和sha256(lfs文件)算出来的hash值。
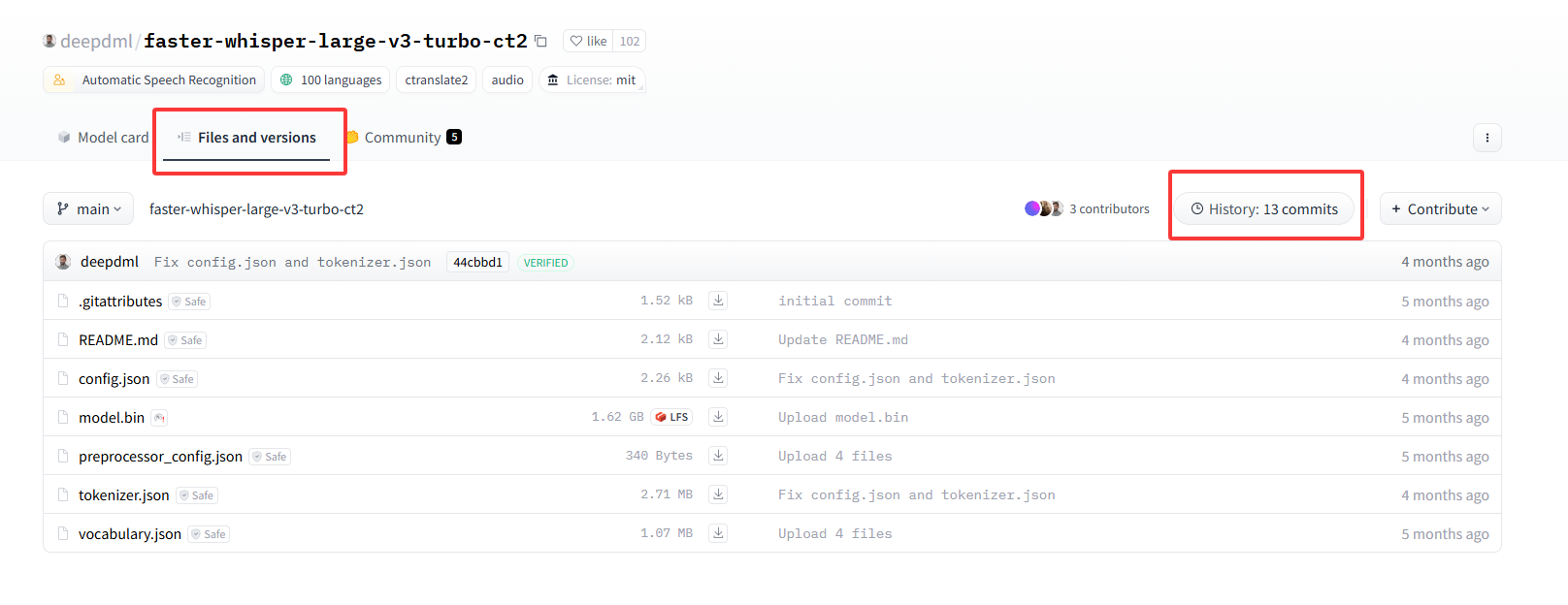
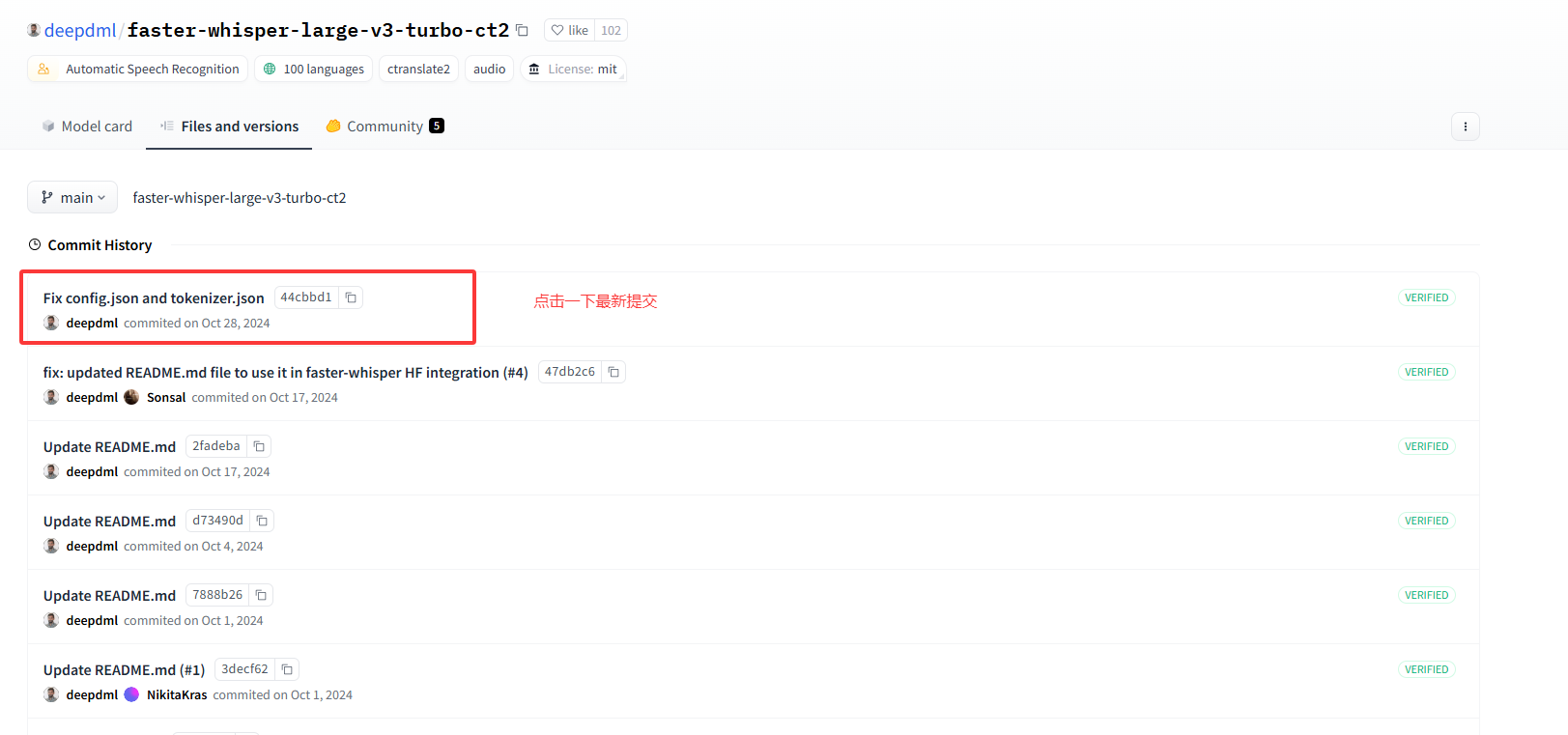
- 以deepdml/faster-whisper-large-v3-turbo-ct2为例,我们先获取它的commit值,打开
Files and versions,点击History xx commits,再点击最上面的最新提交,链接就会将commit显示出来。

- 它的url是
https://huggingface.co/deepdml/faster-whisper-large-v3-turbo-ct2/commit/44cbbd1adefe7387c83df88963a6d9ac4c9adea5,显然commit_id是44cbbd1adefe7387c83df88963a6d9ac4c9adea5 - 根据它的文件分布规律,我们可以写下面的bash脚本(写了思路,实际代码由deepseek生成)。
#!/bin/bash
# 检查是否提供了路径和commit_id参数
if [ -z "$1" ] || [ -z "$2" ]; then
echo "Usage: $0 <path> <commit_id>"
exit 1
fi
target_path=$1
commit_id=$2
# 检查路径是否存在
if [ ! -d "$target_path" ]; then
echo "Error: Path '$target_path' does not exist."
exit 1
fi
# 获取路径的目录名和父目录名
current_dir=$(basename "$target_path")
parent_dir=$(basename "$(dirname "$target_path")")
# 创建目标目录:父目录的同级目录下的 models--${parent_dir}--${current_dir}
models_dir="$(dirname "$(dirname "$target_path")")/models--${parent_dir}--${current_dir}"
mkdir -p "$models_dir"
# 在目标目录下创建 blobs、refs、snapshots 文件夹
mkdir -p "$models_dir/blobs" "$models_dir/refs" "$models_dir/snapshots"
# 在refs目录下创建main文件,并写入commit_id
echo "$commit_id" > "$models_dir/refs/main"
# 在snapshots目录下创建以commit_id命名的文件夹
mkdir -p "$models_dir/snapshots/$commit_id"
# 遍历指定路径下的所有文件
for file in "$target_path"/*; do
# 跳过目录和脚本本身
if [ -d "$file" ] || [ "$(basename "$file")" == "$(basename "$0")" ]; then
continue
fi
# 计算文件大小
file_size=$(stat -c%s "$file")
# 根据文件大小选择不同的哈希算法
if [ "$file_size" -lt 10485760 ]; then
# 小于10M的文件使用git hash-object计算SHA1
hash=$(git hash-object "$file")
else
# 大于等于10M的文件使用sha256sum计算SHA256
hash=$(sha256sum "$file" | awk '{print $1}')
fi
# 将文件复制到目标目录的blobs目录,并以hash值命名
cp "$file" "$models_dir/blobs/$hash"
# 在目标目录的snapshots目录下创建软链接
ln -s "../../blobs/$hash" "$models_dir/snapshots/$commit_id/$(basename "$file")"
done
# 列出目标目录下的所有文件
echo "Created directory structure and files in: $models_dir"
tree "$models_dir"
- 该脚本接收两个参数,一个是本地模型路径,一个是commit_id
- 注意:需要你的本地模型,存放目录结构是:
[拥有者]/项目名,例如:deepdml/faster-whisper-large-v3-turbo-ct2 - 该脚本还可以继续优化,如果我们不删除离线模型的.git目录,则可以通过git命令直接从里面读取出分支信息和最新commit_id。目前是写死了默认分支为main,最新commit_id则需要去网页版查看。
- 运行脚本试试看:
/hfmodel2cache.sh ../models/deepdml/faster-whisper-large-v3-turbo-ct2 44cbbd1adefe7387c83df88963a6d9ac4c9adea5
Created directory structure and files in: ../models/models--deepdml--faster-whisper-large-v3-turbo-ct2
../models/models--deepdml--faster-whisper-large-v3-turbo-ct2
├── blobs
│ ├── 0351d1d6870005e865747b781b5d7c23ea0459cd
│ ├── 0adcd01e7c237205d593b707e66dd5d7bc785d2d
│ ├── 17456db595adc78a973f97d69d8cb50bc87c0b1c
│ ├── 931c77a740890c46365c7ae0c9d350ba3cca908f
│ ├── 9f33237d3eca0db41b9ac80fd60b4b843d61f923
│ └── e76620f83d5f5b69efd3d87e3dc180c1bd21df9fbebacfd4335e5e1efcc018da
├── refs
│ └── main
└── snapshots
└── 44cbbd1adefe7387c83df88963a6d9ac4c9adea5
├── config.json -> ../../blobs/0351d1d6870005e865747b781b5d7c23ea0459cd
├── model.bin -> ../../blobs/e76620f83d5f5b69efd3d87e3dc180c1bd21df9fbebacfd4335e5e1efcc018da
├── preprocessor_config.json -> ../../blobs/931c77a740890c46365c7ae0c9d350ba3cca908f
├── README.md -> ../../blobs/9f33237d3eca0db41b9ac80fd60b4b843d61f923
├── tokenizer.json -> ../../blobs/17456db595adc78a973f97d69d8cb50bc87c0b1c
└── vocabulary.json -> ../../blobs/0adcd01e7c237205d593b707e66dd5d7bc785d2d
- (测试一下)将这个模型拷贝一份到
~/.cache/huggingface/hub目录下,然后我们用python来下载一下这个模型,看看是否直接读取这个cache而不是在线下载(为了保证离线加载,可以加上HF_HUB_OFFLINE=1参数,只让它读取cache)。
# 防止没有这个路径,创建一下,可能会提示目录已经存在
mkdir -p ~/.cache/huggingface/hub
# 拷贝刚刚创建的目录,到huggingface的cache下面
cp -r models--deepdml--faster-whisper-large-v3-turbo-ct2 ~/.cache/huggingface/hub
# 看看能否从cache中离线加载模型
# 参考 https://huggingface.co/deepdml/faster-whisper-large-v3-turbo-ct2
pip install faster_whisper
HF_HUB_OFFLINE=1 python3 -c "from faster_whisper import WhisperModel;WhisperModel('deepdml/faster-whisper-large-v3-turbo-ct2')"
# 可以正常执行完成则说明没有问题,如果半路卡住不动,则说明cache无用或者已经不是最新的commit了,需要更新一下你下载的离线模型。